Algorithm Engineering - Case Study: In einem Tag zum 3D-Cutting-System
- Algorithm Engineering - Case Study: In einem Tag zum 3D-Cutting-System
- Executive Summary
- 1. Das technische OR-Problem
- 2. Zielbild des Systems
- 3. Systemarchitektur
- 4. Iteration 1: Batchfähige Pipeline statt Demo-Skript
- 5. Iteration 2: Greedy-Baseline und Rotation
- 6. Iteration 3: Sägefuge als reale Produktionsbedingung
- 7. Iteration 4: Optimierungssteuerung über dem Packkern
- 8. Iteration 5: Layer -Packing 3D-Optimierung
- 9. Kritischer Bug: Batching innerhalb einer Layer
- 10. Mehrstufige Validierung
- 11. 3D-Visualisierung als Debugging- und Kommunikationswerkzeug
- 12. Teststrategie
- 13. Beispielergebnisse
- 14. Was diese Fallstudie über R&D-Engineering zeigt
- 15. Technische Lessons Learned
- 16. Ergebnis: Ein R&D-Prototyp mit belastbarer Pipeline
- 17. Fazit
- Appendix A: Zielfunktion als Engineering-Modell
- Appendix B: Validierungscheckliste
- Appendix C: Glossar
- Appendix C: Beispiele
Algorithm Engineering - Case Study: In einem Tag zum 3D-Cutting-System
Wie aus einem technischen OR-Problem ein lauffähiger Prototyp für orthogonalen 3D-Zuschnitt wurde ___ Hint: DAs ist eine CAse-Study , um die Fähigkeiten der KI - Coding-Assistenten zu testen, Das reale dazu Produkt existiert schon lange, siehe : https://softwareengel.de/verbesserung-bei-stahl-zuschnitt-durch-anpassung-und-integration-der-3d-verschnitt-optimierung/ s — summary: “Diese Fallstudie beschreibt, wie ein Algorithmus-Experte innerhalb eines kompakten R&D-Sprints ein 3D-Cutting-System für orthogonale Zuschnittprobleme entwickelte: von CSV-Batchverarbeitung über Kerf-Modellierung, Strip-Packing-Algorithmen und Optimierungssteuerung bis hin zu 3D-Visualisierung, Tests und geometrischer Validierung.”
Executive Summary
Ein Algorithmus-Experte erhält ein klassisches, aber industriell sehr reales Problem: Gegebene 3D-Bauteile sollen aus verfügbaren Rohblöcken geschnitten werden. Die Schnitte sind orthogonal, die Bauteile dürfen rotiert werden, der Sägeverlust muss berücksichtigt werden, und das Ergebnis soll als produktionsnaher Schnittplan exportierbar sein. Innerhalb eines kompakten R&D-Sprints entstand daraus ein lauffähiges 3D-Cutting-System mit:
- CSV-Batchverarbeitung für Aufträge und Rohmaterialien
- Greedy-Baseline für schnelle Ergebnisse
- Layer-/Strip-Packing mit 0/1-Knapsack-Komponente
- Sägefugenmodellierung, auch Kerf genannt
- mehrstufiger geometrischer Validierung gegen Überlappung und Containergrenzen
- 3D-Visualisierung als PNG und interaktive Matplotlib-Ansicht
- Unit-Test-Suite für Beispiele, Algorithmen, Kerf, Visualisierung und Bounds-Validation
- CLI-Workflow für wiederholbare Produktionsläufe
Die Arbeit zeigt, wie man ein schweres Operations-Research-Problem pragmatisch in ein belastbares Engineering-Artefakt übersetzt: nicht durch den Versuch, sofort den mathematisch perfekten Solver zu bauen, sondern durch eine kontrollierte Kombination aus Heuristik, dynamischer Programmierung, Validierung und testgetriebener Iteration.
1. Das technische OR-Problem
Das zugrunde liegende Problem gehört zur Familie der multidimensionalen Bin-Cutting- und Bin-Packing-Probleme. In dieser Fallstudie betrachten wir eine 3D-Variante:
- Es gibt eine Menge von Aufträgen
I. - Jeder Auftrag
iist ein Quader mit Dimensionen(l_i, w_i, h_i). - Es gibt eine Menge von Rohblöcken
B. - Jeder Rohblock
bist ein Quader mit Dimensionen(L_b, W_b, H_b). - Ein Auftrag darf in orthogonalen Rotationen platziert werden.
- Platzierungen dürfen sich nicht überschneiden.
- Jede Platzierung muss vollständig innerhalb eines Rohblocks liegen.
- Zwischen Schnitten entsteht Materialverlust durch die Sägefuge.
- Nicht platzierte Aufträge sind stark zu bestrafen.
1.1 Orthogonaler 3D-Zuschnitt
Im orthogonalen Zuschnitt sind alle Schnitte achsenparallel. Ein platziertes Teil wird daher durch folgende Größen beschrieben:
placement_i = (block_id, x_i, y_i, z_i, l_i', w_i', h_i')
Dabei ist (x_i, y_i, z_i) die untere linke hintere Ecke im Rohblock und (l_i', w_i', h_i') ist eine gültige Rotation der Originaldimensionen.
Die einfachen Bounds-Constraints lauten:
0 <= x_i
0 <= y_i
0 <= z_i
x_i + l_i' <= L_b
y_i + w_i' <= W_b
z_i + h_i' <= H_b
Für jedes Paar platzierter Teile i und j im selben Rohblock gilt zusätzlich eine Nicht-Überlappungsbedingung. Mindestens eine der folgenden Relationen muss wahr sein:
i liegt links von j: x_i + l_i' <= x_j
i liegt rechts von j: x_j + l_j' <= x_i
i liegt vor j: y_i + w_i' <= y_j
i liegt hinter j: y_j + w_j' <= y_i
i liegt unter j: z_i + h_i' <= z_j
i liegt über j: z_j + h_j' <= z_i
Das ist bereits ohne zusätzliche Produktionsbedingungen ein schweres kombinatorisches Problem. In der Praxis kommen weitere Anforderungen hinzu: Sägeverlust, Schnittpläne, robuste Reports, visuelle Kontrolle, Laufzeitgrenzen und nachvollziehbare Fehlermeldungen.
2. Zielbild des Systems
Das Ziel war kein akademischer Paper-Solver, sondern ein R&D-Prototyp mit Produktionsnähe:
- Daten rein: Aufträge und Rohblöcke als CSV.
- Algorithmus ausführen: Greedy oder Layer-inspiriertes Packing.
- Ergebnis raus: Schnittplan, Report, Visualisierung.
- Qualität prüfen: Unit Tests, Volumenerhaltung, Bounds, keine Überlappung.
- Iterierbarkeit sichern: CLI, reproduzierbare Beispiele, klare Projektstruktur.
Der entscheidende Engineering-Grundsatz war: Erst eine korrekte Pipeline, dann bessere Optimierung.
3. Systemarchitektur
Die finale Architektur lässt sich in sechs Schichten beschreiben.
┌──────────────────────────────────────────────┐
│ CLI / Batch Workflow │
│ orders.csv + raw_blocks.csv + options │
└──────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────┐
│ Input / Output Layer │
│ CSV loader, cut_plan.csv, report.txt, PNG │
└──────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────┐
│ Packing Core │
│ Greedy baseline + rotations + free spaces │
└──────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────┐
│ Optimization Steering │
│ assignment strategies, scoring, caching │
└──────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────┐
│ Layer Packing │
│ layer heights, strip packing, knapsack DP │
└──────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────┐
│ Validation & Visualization │
│ bounds, overlap, volume conservation, 3D plots │
└──────────────────────────────────────────────┘
4. Iteration 1: Batchfähige Pipeline statt Demo-Skript
Der erste Schritt war die Umwandlung eines interaktiven Demo-Optimierers in eine batchfähige Softwarekomponente.
4.1 Eingabeformat
Für Aufträge und Rohblöcke wurde bewusst dasselbe CSV-Schema verwendet:
id,length,width,height
ORD-001,20,15,10
ORD-002,25,20,12
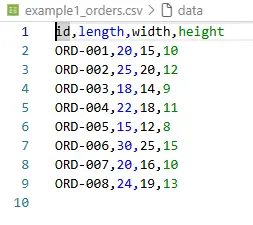
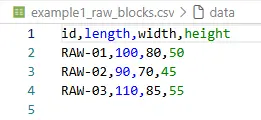 Das senkt die kognitive Last und macht Beispiele leicht erzeugbar.
Das senkt die kognitive Last und macht Beispiele leicht erzeugbar.
4.2 Ausgabeformate
Der Batchlauf erzeugt drei zentrale Artefakte:
<prefix>_cut_plan.csv
<prefix>_report.txt
<prefix>_<RAW-ID>_layout.png
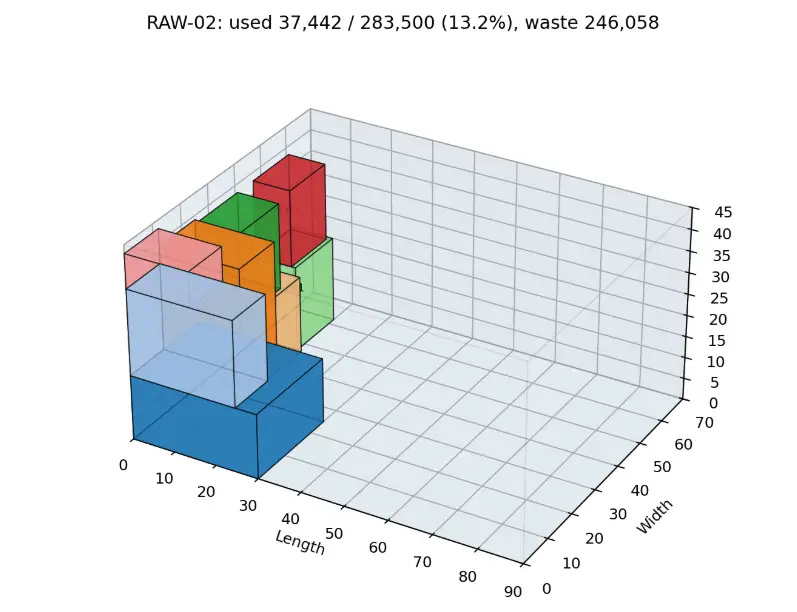
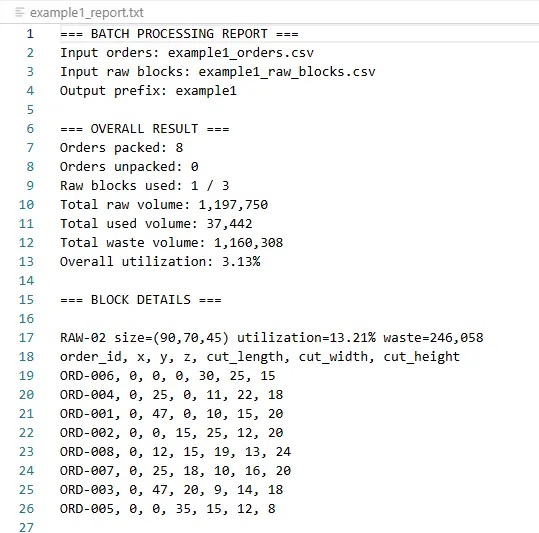

Der cut_plan.csv ist für nachgelagerte Produktions- oder CNC-nahe Prozesse gedacht. Er enthält:
- Rohblock-ID und Rohblockdimensionen
- Auftrags-ID
- Platzierungskoordinaten
(x, y, z) - geschnittene Dimensionen
- Originaldimensionen zur Nachverfolgbarkeit
- später ergänzt: Kerf- und Restmaterialkennzahlen
Damit wurde aus dem Algorithmus ein wiederholbarer Batchprozess.
5. Iteration 2: Greedy-Baseline und Rotation
Eine robuste Baseline ist im Operations Research oft wertvoller als ein unausgereifter Meta-Solver. Die Greedy-Variante arbeitet nach folgendem Prinzip:
- Sortiere Aufträge nach Volumen.
- Versuche pro Auftrag alle orthogonalen Rotationen.
- Suche einen passenden freien Raum.
- Platziere das Teil.
- Teile den verbleibenden Raum guillotine-artig in neue Freiräume.
- Wiederhole, bis keine Platzierung mehr möglich ist.
5.1 Warum Greedy zuerst?
Greedy ist nicht global optimal, aber:
- schnell
- deterministisch
- einfach testbar
- guter Vergleichsmaßstab
- hilfreich für Regressionstests
In den frühen Beispielen lieferte diese Baseline bereits verwendbare Ergebnisse, etwa vollständige Packungen für kleine und mittlere Datasets.
6. Iteration 3: Sägefuge als reale Produktionsbedingung
Ein theoretisches Packing ohne Sägeverlust ist in der Fertigung irreführend. Deshalb wurde die Sägefuge, also der Kerf, explizit modelliert.
6.1 Modellierungsentscheidung
Für jede Platzierung wird Materialverlust über Schnittflächen abgeschätzt:
kerf_loss = (l × w + l × h + w × h) × saw_width
Zusätzlich reserviert die Freiraumaufteilung Abstand durch die Sägefuge, sodass benachbarte Teile nicht unrealistisch kantenbündig ohne Materialverlust geplant werden.
6.2 Volumenbilanz
Nach Einführung des Kerf musste die Volumengleichung angepasst werden:
total_volume = used_volume + kerf_waste + other_waste
Diese einfache Gleichung wurde zu einem zentralen Testkriterium. Sie verhindert, dass Material durch Rechenfehler „verschwindet“ oder doppelt gezählt wird.
7. Iteration 4: Optimierungssteuerung über dem Packkern
Ein einzelner Greedy-Lauf beantwortet nur die Frage: „Was passiert bei dieser Reihenfolge?“ Das eigentliche Produktionsproblem fragt aber: „Welche Zuordnung von Aufträgen zu Rohblöcken ist insgesamt besser?“
Dafür wurde eine Optimierungssteuerung über den Packkern gelegt.
7.1 Strategien
Die Steuerung erzeugt mehrere Kandidatenlösungen, zum Beispiel:
- Sortierung nach größter Dimension
- Sortierung nach kleinster Dimension
- Sortierung nach Oberfläche
- Sortierung nach Aspektverhältnis
- zufällige, reproduzierbare Shuffles
- Round-Robin-Zuordnung
- Größenbasierte Block-Affinität
7.2 Deduplication
Viele Strategien können dieselbe effektive Zuordnung erzeugen. Deshalb wurde ein Hash-basiertes Cache-System eingeführt:
assignment_hash = hash(order_id -> block_id)
So werden doppelte Lösungen erkannt, übersprungen und die Laufzeit sinkt.
7.3 Scoring
Die Bewertung einer Lösung kombiniert mehrere Ziele:
score =
utilization_weight
- blocks_used_penalty
- unpacked_orders_penalty
- waste_variance_penalty
- kerf_penalty
Ein wichtiger Bugfix bestand darin, Volumenwerte nicht roh in Millionen Kubikmillimetern zu bestrafen, sondern zu normalisieren. Erst dadurch wurden Scores wieder interpretierbar und die Steuerung konnte schlechtere Lösungen zuverlässig ablehnen.
8. Iteration 5: Layer -Packing 3D-Optimierung
Für anspruchsvollere Fälle wurde eine Layer-Packing - Methode implementiert. Der Ansatz greift Ideen aus dem Container-Loading-Problem auf und kombiniert sie mit pragmatischen Python-Optimierungen.
8.1 Algorithmische Bausteine
Der implementierte Ansatz besteht aus:
-
Layer Packing Der Rohblock wird entlang der z-Achse in Schichten zerlegt.
-
Box Rotation & Pairing Teile werden für eine Layerhöhe rotiert. Kompatible Teile können gepaart werden, um Schichthöhen besser auszunutzen.
-
Recursive Strip Packing Eine 2D-Schicht wird rekursiv in Streifen zerlegt.
-
0/1-Knapsack pro Strip Innerhalb eines Streifens entscheidet ein dynamischer Programmierer, welche Boxen den Streifen am besten füllen.
-
Integration Layer Zwischen bestehendem Optimizer-Datenmodell und Layer Packing Datenstrukturen vermittelt ein Konvertierungsmodul.
8.2 Vereinfachtes Pseudocode-Modell
function pack_orders_layer(orders, raw_blocks):
remaining = orders
for block in raw_blocks:
z = 0
while z < block.height and remaining not empty:
layer_height = choose_layer_height(remaining, block, z)
candidates = select_candidate_boxes(remaining, limit=MAX_BOXES_PER_LAYER)
prepared = rotate_and_pair(candidates, layer_height)
placements = pack_layer_with_strips(prepared, block.length, block.width, z)
valid = validate_bounds(placements, block)
commit(valid)
remove_committed_orders(remaining)
z += layer_height
return blocks, remaining_as_unpacked
8.3 Warum kein vollständiger exakter Solver?
Ein vollständiger Branch-and-Bound-Ansatz kann in Python schnell zu langsam werden. Die Entscheidung fiel daher auf einen hybriden Ansatz:
- Kernideen aus Layer - Packing übernehmen
- Laufzeit durch Limits kontrollieren
- Korrektheit durch Validierung erzwingen
- Verbesserungen messbar und testbar halten
Das Ergebnis ist kein mathematischer Optimalitätsbeweis, aber ein R&D-tauglicher Optimierer mit sauberer Fehlerkontrolle.
9. Kritischer Bug: Batching innerhalb einer Layer
Ein besonders lehrreicher Fehler trat beim Skalieren des Layer-Packing-inspirierten Packings auf.
9.1 Der Fehler
Zur Laufzeitkontrolle wurden Boxen in Batches gepackt. Die fehlerhafte Variante führte aber mehrere Packing-Aufrufe innerhalb derselben Layer aus:
while remaining_to_pack:
batch = remaining_to_pack[:MAX_BOXES_PER_ATTEMPT]
placements, waste = pack_layer_simple(...)
all_placements.extend(placements)
Alle Batches starteten bei denselben Layer-Koordinaten. Dadurch konnten mehrere Teile denselben Raum belegen oder über die Blockgrenze hinausragen.
9.2 Die Korrektur
Die Korrektur bestand darin, nur einen Packing-Aufruf pro Layer zuzulassen und stattdessen die Kandidatenmenge pro Layer zu begrenzen:
boxes_for_layer = all_boxes_to_pack[:MAX_BOXES_PER_LAYER]
placements, waste = pack_layer_simple(
boxes=boxes_for_layer,
layer_width=block.box.l,
layer_depth=block.box.w,
layer_z=current_z,
layer_height=layer_height
)
Das ist ein klassischer R&D-Lerneffekt: Performance-Optimierung darf die geometrische Semantik des Problems nicht verletzen.
10. Mehrstufige Validierung
Nach dem Batching-Bug wurde die Validierung bewusst redundant ausgelegt.
10.1 Validierung während des Strip Packings
Jede Placement-Kandidatur wird gegen die Containergrenzen geprüft:
px >= 0
py >= 0
z >= 0
px + length <= container_l
py + width <= container_w
z + height <= container_h
Ungültige Platzierungen werden gar nicht erst in die Kandidatenlösung aufgenommen.
10.2 Validierung in der Integration
Beim Zurückkonvertieren in das Hauptdatenmodell wird erneut geprüft, ob die Platzierung im Rohblock liegt.
10.3 Post-Processing-Validierung
Ein eigenständiges Tool validiert den exportierten cut_plan.csv. Das ist wichtig, weil genau dieses Artefakt später in Produktions- oder Visualisierungsprozesse eingeht.
Die drei Validierungsstufen sind:
1. Während der Suche: ungültige Kandidaten vermeiden
2. Vor dem Commit: ungültige Placements abfangen
3. Nach dem Export: Schnittplan unabhängig prüfen
Damit wird aus einem experimentellen Algorithmus ein belastbares Systemartefakt.
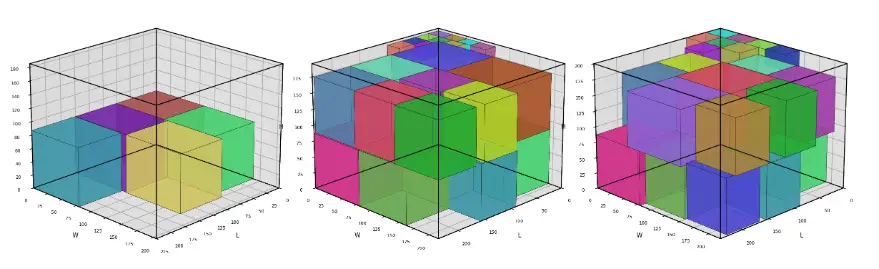
11. 3D-Visualisierung als Debugging- und Kommunikationswerkzeug
Die Visualisierung war nicht nur „nice to have“. Sie erfüllte drei Funktionen:
- Debugging: Überlappungen und Bounds-Fehler sind visuell schnell erkennbar.
- Validierung: Stakeholder können Schnittpläne nachvollziehen.
- Kommunikation: R&D-Ergebnisse werden anschaulich.
11.1 Visualisierungselemente
Die 3D-Plots zeigen:
- transparente Rohblock-Wireframes
- farbige Auftragsquader
- Order-ID-Labels
- Nutzungs-, Rest- und Kerf-Kennzahlen
- Zusammenfassungen über alle verwendeten Blöcke
11.2 Batchausgabe
Für einen Lauf entstehen:
3d_plots/
├── example_RAW-01.png
├── example_RAW-02.png
└── example_summary.png
Für größere Beispiele wurden mehrere Blockplots plus Summary-Plot generiert. Damit wird der Schnittplan als Bild prüfbar, ohne die CSV manuell zu analysieren.
12. Teststrategie
Die Teststrategie wurde schrittweise erweitert.
12.1 Frühe Tests
Die erste Suite validierte:
- CSV-Loading
- Anzahl geladener Orders und Rohblöcke
- Anzahl gepackter und ungepackter Aufträge
- Volumenberechnungen
- Utilization
- keine Überlappungen
- Bounds
- Volumenerhaltung
12.2 Kerf-Tests
Nach Einführung der Sägefuge kamen Tests hinzu für:
- positives Kerf-Waste bei
saw_width > 0 - keine Kerf-Verluste bei
saw_width = 0 - korrekte Volumenbilanz inklusive Kerf
- Kapazitätsreduktion durch Sägefuge
12.3 Layer - Packing-Tests
Für die Layer-Packing-inspirierten Komponenten wurden getrennte Tests erstellt:
- Knapsack Solver
- Box Preparation
- Box Rotation
- Pairing
- Strip Packing
- Integration
- Vermeidung doppelter Placements
12.4 Visualisierungstests
Auch die Visualisierung wurde testbar gemacht:
- Erzeugung von Box-Faces
- Farbgenerierung
- PNG-Ausgabe
- Summary-Plot
- große Datasets
- Fälle mit ungepackten Aufträgen
Das Ergebnis ist eine Testkette, die algorithmische und geometrische Fehler früh sichtbar macht.
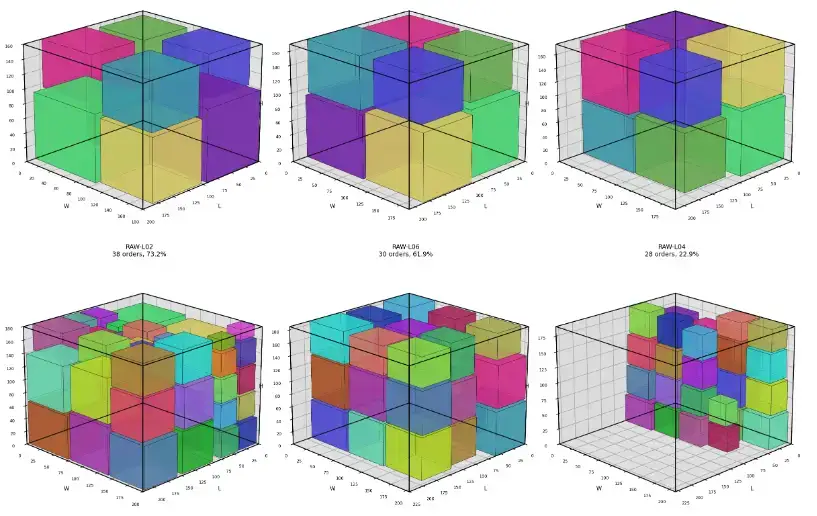
13. Beispielergebnisse
Die folgenden Ergebnisse stammen aus den Entwicklungs- und Validierungsläufen des Systems. Sie sind keine universellen Benchmarks, sondern zeigen, dass die Pipeline für unterschiedlich große Fälle funktioniert.
| Beispiel | Aufträge | Rohblöcke | Ergebnis |
|---|---|---|---|
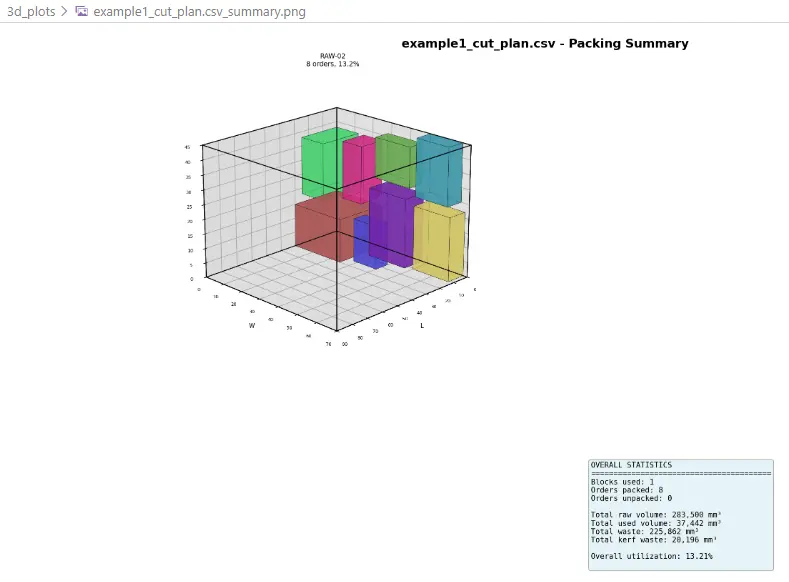
| Example 1 | 8 | 3 | 8/8 gepackt, 1 Block verwendet, ca. 3,13 % Gesamtausnutzung |
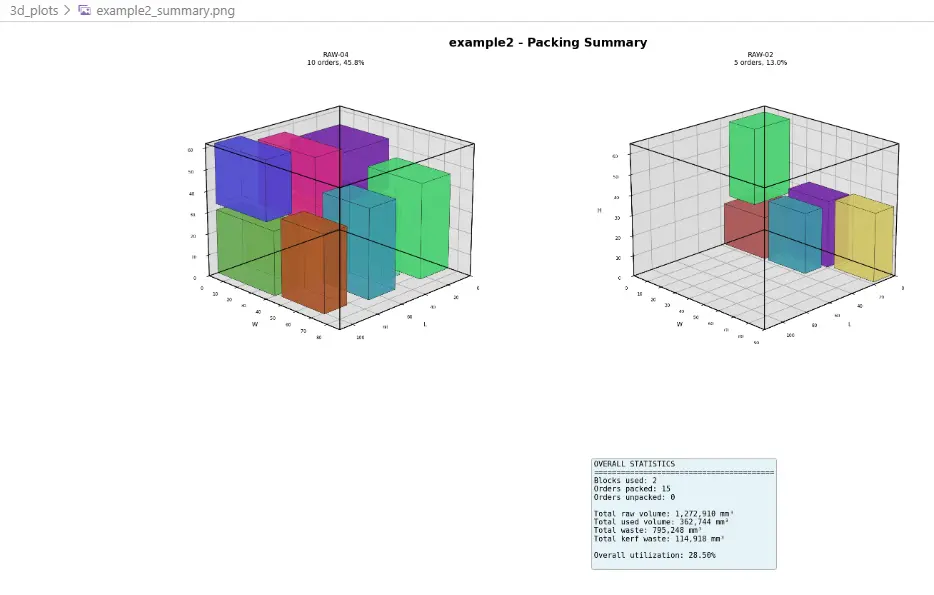
| Example 2 | 15 | 5 | 15/15 gepackt, 2 Blöcke verwendet, ca. 9,24 % Gesamtausnutzung |
| Example 3 | 25 | 4 | je nach Konfiguration teilweise ungepackte Aufträge; gut geeignet als Stressfall |
| Example 4 | 131 | 10 | nach Bounds-Fix 131/131 gepackt, 5 Blöcke verwendet, 35,54 % Ausnutzung |
| Example 5 | 40 | 6 | nach Bounds-Fix 40/40 gepackt, 1 Block verwendet, 8,19 % Ausnutzung |
Die niedrigen Gesamtausnutzungen einzelner Beispiele sind kein Fehler: Wenn die Rohblockmenge deutlich größer als das Auftragsvolumen ist, fällt die globale Ausnutzung naturgemäß niedrig aus. Aussagekräftiger ist dann die Kombination aus:
- Anzahl vollständig erfüllter Aufträge
- Anzahl verwendeter Rohblöcke
- Ausnutzung pro verwendetem Block
- Materialverlust durch Kerf
- Korrektheit der Platzierungen
14. Was diese Fallstudie über R&D-Engineering zeigt
14.1 Ein schweres Problem wird durch Schichtung beherrschbar
Statt sofort einen monolithischen Solver zu bauen, wurde das Problem zerlegt:
I/O → Greedy → Steering → Layer-Komponenten → Validation → Visualization
Jede Schicht lieferte eigenständigen Wert.
14.2 Korrektheit ist wichtiger als scheinbare Optimierung
Ein schneller Algorithmus, der Teile außerhalb des Rohblocks platziert, ist wertlos. Erst die Bounds-Validation machte das System belastbar.
14.3 Visualisierung beschleunigt Forschung
3D-Plots sind nicht nur Präsentationsmaterial. Sie sind ein Debugging-Instrument für räumliche Algorithmen.
14.4 Tests sind Teil des Algorithmus
Bei geometrischer Optimierung reicht es nicht, nur Funktionsaufrufe zu testen. Man muss Invarianten testen:
keine Überlappung
innerhalb der Bounds
Volumenbilanz korrekt
keine doppelten Orders
ungepackte Orders explizit ausgewiesen
14.5 Heuristik plus Validierung schlägt naive Exaktheit
Für einen R&D-Prototyp ist ein kontrollierter heuristischer Solver oft produktiver als ein zu langsamer exakter Ansatz. Wichtig ist, dass die Heuristik ihre Fehler nicht versteckt.
15. Technische Lessons Learned
Lesson 1: Normalize before scoring
Ein Score, der Rohvolumina in Kubikmillimetern direkt mit kleinen Penalty-Werten kombiniert, kann numerisch unsinnig werden. Normalisierte Kennzahlen machen die Zielfunktion interpretierbar.
Lesson 2: Layer-Semantik respektieren
Batching darf nicht innerhalb derselben geometrischen Layer mehrere unabhängige Koordinatensysteme erzeugen. Eine Layer braucht genau einen konsistenten Packing-Aufruf oder ein explizites Subraum-Modell.
Lesson 3: Redundante Validierung ist kein Overhead, sondern Sicherheitsnetz
Die gleiche Bounds-Regel an mehreren Stellen zu prüfen, wirkt redundant. In einem Optimierungssystem mit mehreren Konvertierungsschichten ist es aber der Unterschied zwischen Debugging und Vertrauen.
Lesson 4: Ein guter Baseline-Solver bleibt wertvoll
Auch nach Einführung von Layer-Packing-inspirierten Komponenten bleibt Greedy wichtig:
- als Fallback
- als Vergleich
- als schneller Plausibilitätscheck
- als Regressionstest
Lesson 5: Produktionsnähe beginnt bei Dateiformaten
CSV rein, CSV/Report/PNG raus: Diese einfache Entscheidung machte das System sofort nutzbar, testbar und erklärbar.
16. Ergebnis: Ein R&D-Prototyp mit belastbarer Pipeline
Am Ende des Sprints stand kein theoretisches Optimum, sondern ein funktionsfähiges 3D-Cutting-System:
python main.py example1_orders.csv example1_raw_blocks.csv example1 \
--saw-width 3 \
--visualize \
--verbose
oder für optimierte Läufe:
python main.py example3_orders.csv example3_raw_blocks.csv example3_optimized \
--optimize \
--max-time 30 \
--max-iter 50 \
--saw-width 3 \
--visualize
Das System kann Auftragsdaten laden, Rohblöcke auswählen, 3D-Platzierungen berechnen, Sägeverlust berücksichtigen, Schnittpläne exportieren, Visualisierungen erzeugen und seine Ergebnisse geometrisch validieren.
17. Fazit
Diese Case Study zeigt, wie ein Algorithmus-Experte ein komplexes technisches OR-Problem innerhalb eines sehr kurzen Zeitfensters in Software übersetzen kann.
Der Schlüssel war nicht ein einzelner genialer Algorithmus, sondern die Kombination aus:
- sauberer Problemformulierung
- schneller Greedy-Baseline
- Layer-Packing-inspirierten Optimierungskomponenten
- realistischen Fertigungsbedingungen wie Kerf
- konsequenter Validierung
- Visualisierung
- automatisierten Tests
- iterativem Debugging
Das Ergebnis ist ein Muster für moderne R&D-Softwareentwicklung: wissenschaftlich inspiriert, pragmatisch implementiert und durch Tests gegen die Realität abgesichert.
Appendix A: Zielfunktion als Engineering-Modell
Eine produktionsnahe Zielfunktion kann wie folgt modelliert werden:
maximize score =
α × utilization
- β × used_blocks
- γ × unpacked_orders
- δ × normalized_waste_variance
- ε × kerf_ratio
Typische Priorität:
- Keine ungepackten Aufträge
- Keine ungültigen Platzierungen
- Weniger Rohblöcke
- Bessere Ausnutzung
- Weniger Kerf
- Gleichmäßigere Restmaterialverteilung
Wichtig: Ungültige Platzierungen sollten nie nur „bestraft“ werden. Sie müssen ausgeschlossen werden.
Appendix B: Validierungscheckliste
Vor Veröffentlichung eines Schnittplans sollte das System prüfen:
- Alle Placement-Koordinaten sind nicht-negativ.
- Jedes Teil liegt vollständig im Rohblock.
- Keine zwei Teile überlappen sich.
- Jede Order-ID wird höchstens einmal gepackt.
- Nicht platzierte Orders werden explizit ausgegeben.
used + kerf + waste = total.- Der CSV-Schnittplan ist unabhängig validierbar.
- Die 3D-Visualisierung zeigt dieselbe Lösung wie der CSV-Export.
Appendix C: Glossar
3D Cutting Problem Optimierungsproblem, bei dem dreidimensionale Teile aus dreidimensionalem Rohmaterial zugeschnitten werden.
Bin Packing Problemklasse, bei der Objekte in möglichst wenige Container gepackt werden sollen.
Bin Cutting Verwandte Problemklasse mit Fokus auf Zuschnitt, Materialverlust und Schnittplan.
Kerf Materialverlust durch die Breite des Sägeblatts oder Schnittwerkzeugs.
Guillotine Cut Schnitt, der vollständig durch ein verbleibendes Materialstück verläuft.
Strip Packing 2D-Packverfahren, bei dem eine Fläche in Streifen aufgeteilt wird.
0/1-Knapsack Optimierungsproblem, bei dem aus einer Menge von Objekten eine Teilmenge unter Kapazitätsgrenze mit maximalem Nutzen gewählt wird.
Bounds Validation Prüfung, ob platzierte Geometrien vollständig innerhalb ihrer Containergrenzen liegen.
Utilization Verhältnis von verwendetem Materialvolumen zu verfügbarem Rohmaterialvolumen.
Appendix C: Beispiele
Beispiel 1 - 3D Cutting Summary
Beispiel 2 - 3D Cutting Summary
Beispiel 3 - 3D Cutting Summary
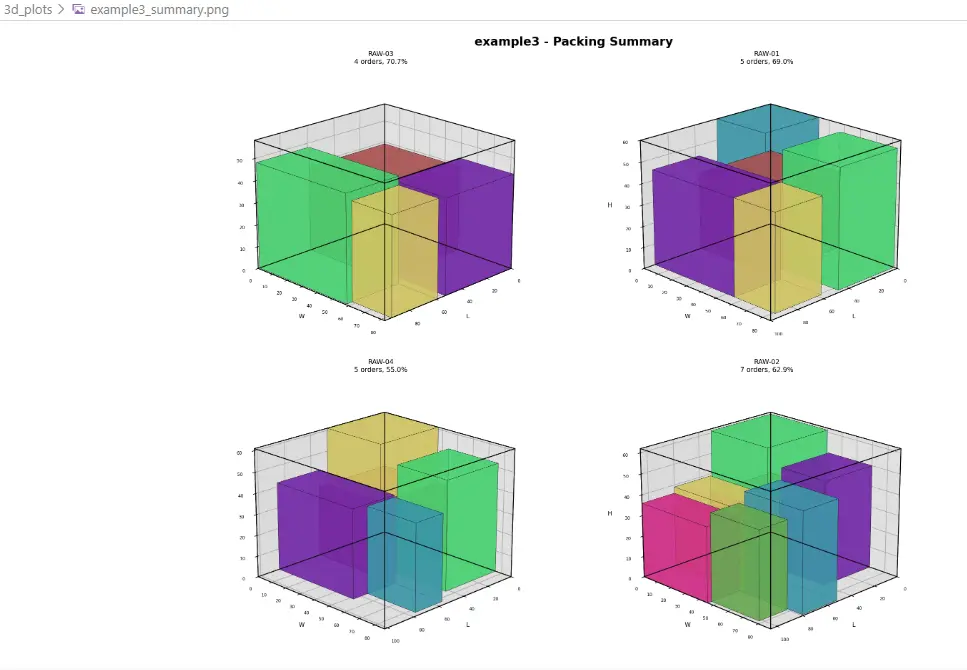
Beispiel 4 - 3D Cutting Summary
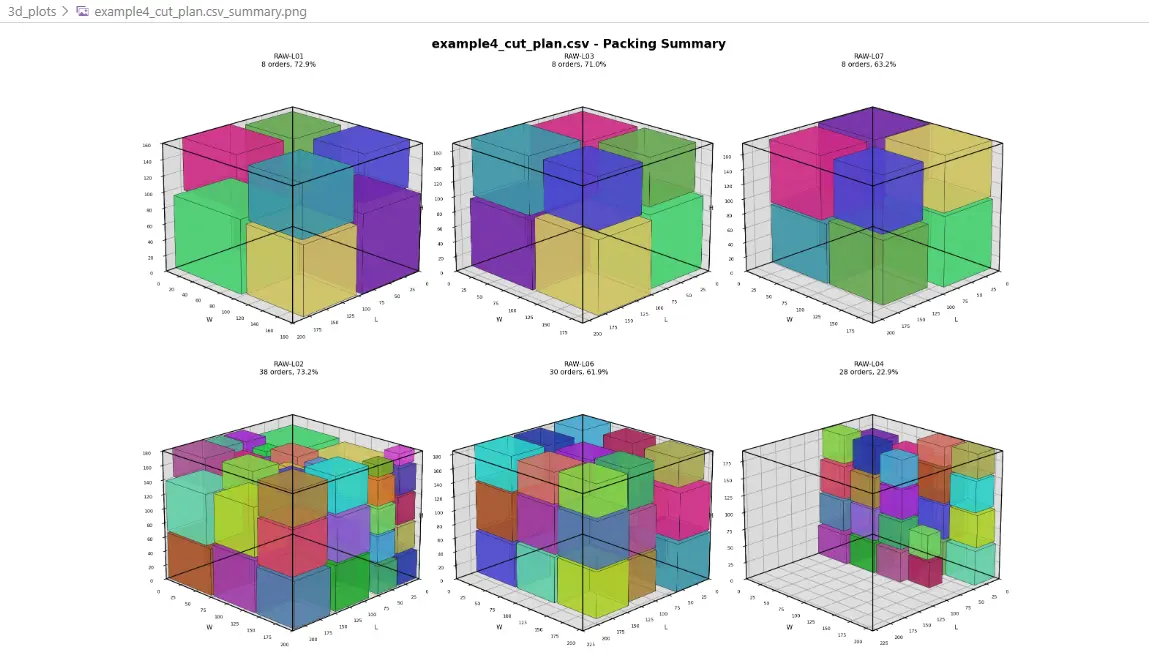
Beispiel 4b - 3D Cutting Summary
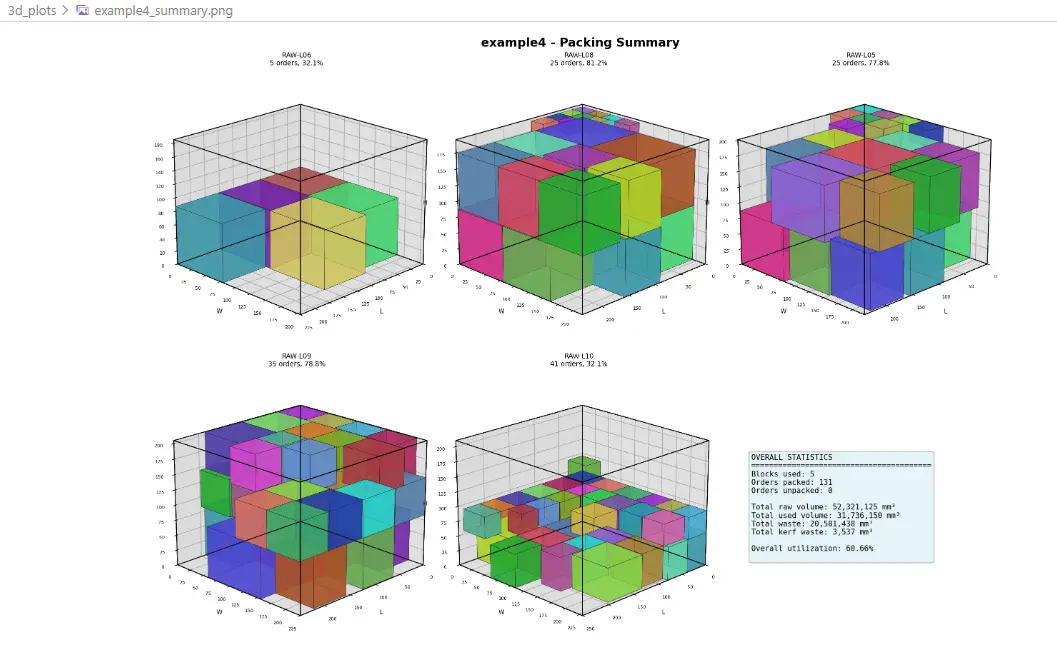
Beispiel 5 - 3D Cutting Summary
